From Sessions to JWTs: How Distributed Systems Reshaped Identity
I am here to share everything I know about computer systems: from the internals of CPUs, memory, and storage engines to distributed systems, OS design, blockchain, AI etc. Deep dives, hands-on experiments, and clarity-first explanations.
The evolution of identity mechanisms closely followed the evolution of distributed systems. This article walks through that progression and the problems each step tried to solve.
Before Identity (Early–Mid 1990s)
In early web applications, identity was not an explicit concept. Applications ran on a single server with limited traffic and concurrency. A client’s connection to the server implicitly represented the user, and the server process could safely assume who it was communicating with.
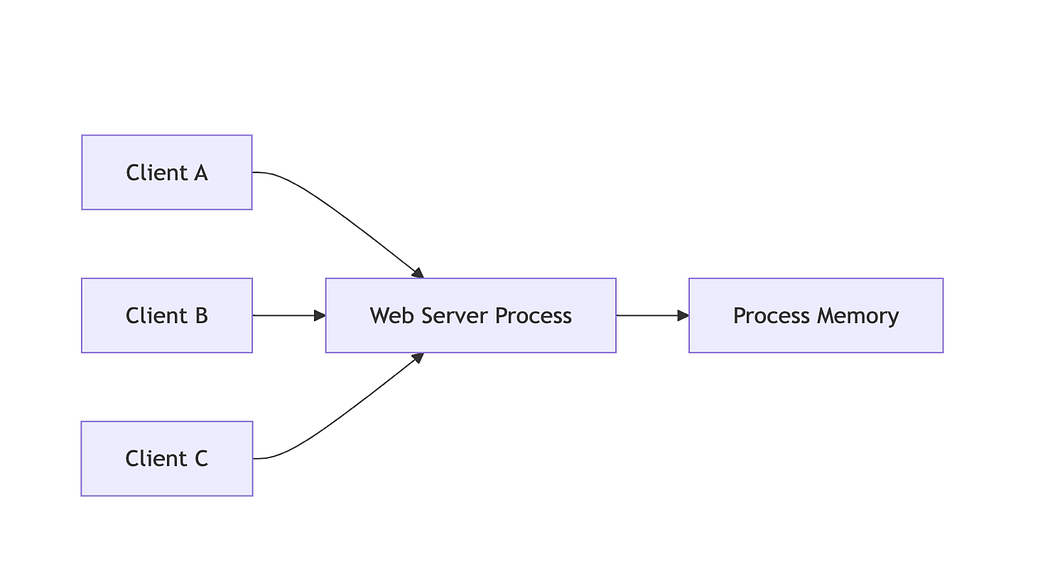
What changed
HTTP introduced a stateless request model. Each request was handled independently, without relying on a persistent connection. As a result, the server could no longer infer user identity from the connection alone.
HTTP and Statelessness (Mid–Late 1990s)
HTTP is stateless. Each request is handled independently and carries no information about previous requests. Because of this, the server cannot tell whether two requests come from the same user.
HTTP did not remove identity support; it simply did not include it. Identity management was left to applications built on top of the protocol.
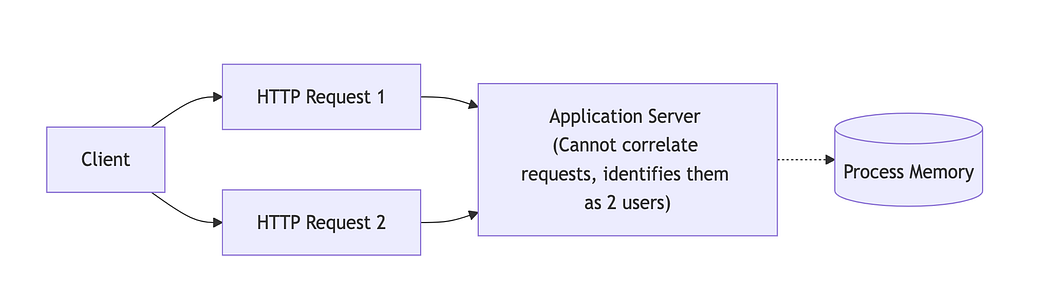
What changed
Applications needed to restore continuity above HTTP, without modifying the protocol itself. The earliest attempts were explicit and application-controlled.
Sessions: Restoring Continuity (Late 1990s–Early 2000s)
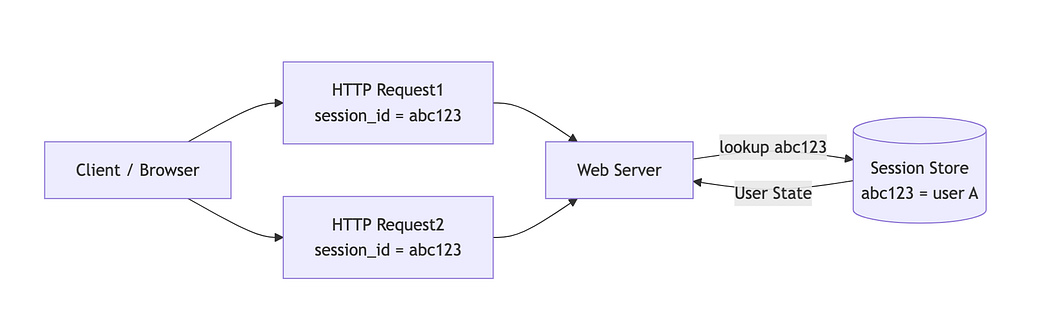
Sessions reintroduced continuity at the application layer. The model was as follows :-
When a user begins interacting with the application, the server creates a session.
The session stores user-related state on the server.
The session is identified by a session ID, a random, opaque identifier.
This was a pure server-side invention. At this point:
The session ID existed only as a concept.
The server had no built-in way to see the same session again on later requests. So they needed some way to receive it on future requests.
Sessions worked by assuming the server could remember user state between requests.
What changed
To use sessions, the server needed a way to receive the session ID back from the client on every request. This forced the next question:
How do we carry the session ID across HTTP requests?
Carrying the Session ID: URLs, Forms, and Cookies (Late 1990s–Early 2000s)
Once sessions existed, multiple transport mechanisms emerged. All of them attempted to answer the same question:
How does the client send the session ID back to the server?
Option 1: URL rewriting
/profile?session_id=abc123
Option 2: Hidden form fields
<input type=”hidden” name=”session_id” value=”abc123">
Option 3: Cookies
Cookie: session_id=abc123
Why URL Rewriting/Hidden form fields Failed (and Cookies Won)
URL rewriting and hidden fields failed because they didn’t match how the web actually works.
They quietly assumed that :-
The application controls navigation.
The links are not shared.
URLs are not bookmarked.
Every request follows a predictable path.
The real web violates all of these assumptions. As a result:
Session IDs leaked through URLs, logs, and referrers.
Bookmarks and shared links carried identity.
Identity became visible, fragile, and easy to misuse.
These approaches required every link and form to preserve the identifier, which could not be reliably enforced on the web. Cookies work because they are scoped (domain, path, SameSite) and are not sent cross-site unless explicitly allowed + the browser handles this automatically. The identifier was sent with each request without being exposed in URLs or application logic.
Clear separation emerged:
sessions defined identity,
cookies carried the session ID
What changed
This model worked well → as long as the backend remained a single logical system. Then systems began to distribute.
Distributed Backends and the Limits of Sessions (Mid — Late 2000s)
Applications began scaling horizontally. Requests from the same user could now land on different servers. Process memory was no longer shared. Sessions still worked → but only with following extra infrastructure :-
Sticky Sessions (Multiple Servers)
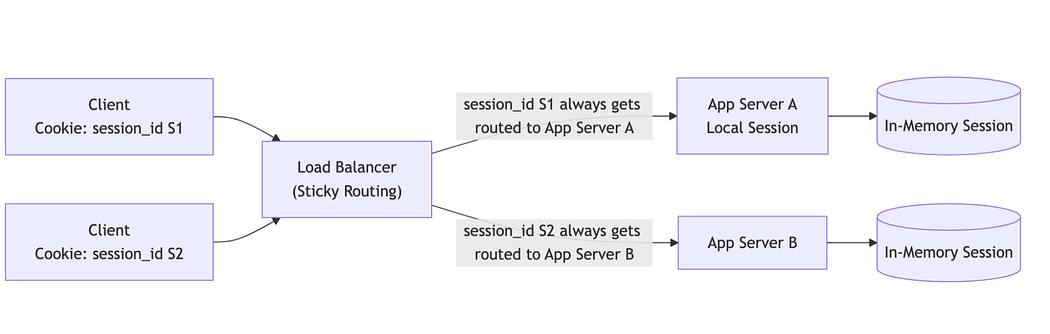
What it solved
Session state was stored locally on the server.
No distributed session store was required.
Session access was simple and fast.
What it broke
Requests had to return to the same server.
Load balancing became uneven.
Server restarts caused session loss.
Scaling and failover were constrained.
Centralized Session Store (Multiple Servers)
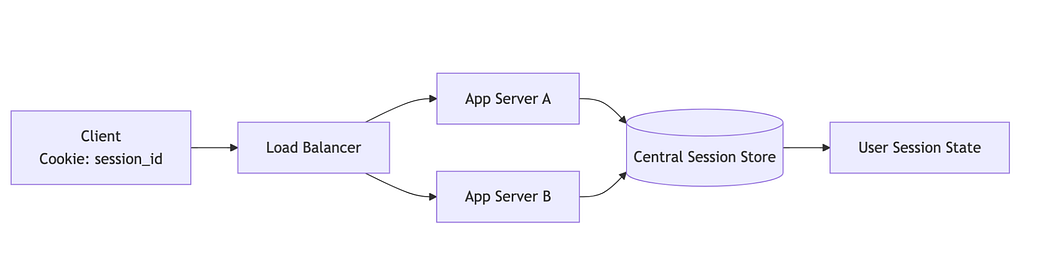
What it solved
Session state could be shared across multiple servers.
Requests no longer needed to return to the same machine.
Horizontal scaling of application servers became possible.
What it broke
Additional network latency on every request.
A shared dependency for all application servers.
A single failure domain without any replication.
Centralized Auth Service (Microservices)
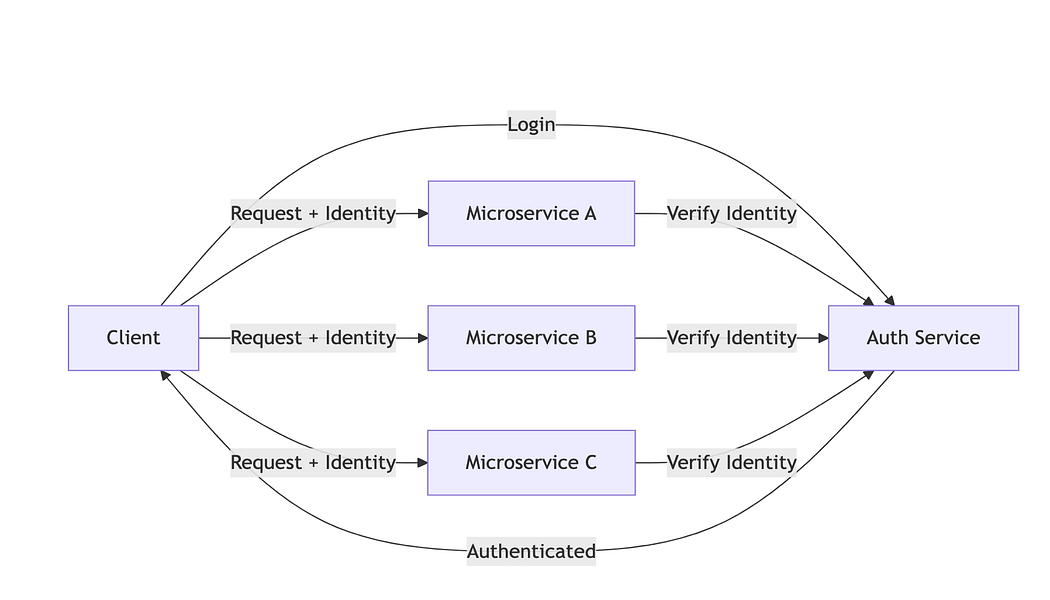
What it solved
Authentication logic was implemented once.
Consistent identity checks across services.
Microservices stayed focused on business logic.
Sessions could be reused across services.
What it broke
Every request depended on the auth service.
Auth became a runtime bottleneck.
Auth service became a shared failure domain.
Latency increased with service-to-service hops.
Internal services could not verify identity independently.
What changed
Systems needed a way for identity to travel with the request, without contacting the auth service every time.
Meanwhile, there was one more shift going on in parallel :-
Applications were no longer accessed only by browsers.
APIs became first-class interfaces.
Clients included mobile apps, server-to-server calls, CLI tools and third-party integrations
This broke a core assumption of the cookie/session model: The client is always a browser that automatically manages cookies.
This led to tokens.
Tokens (Opaque): Identity Becomes an Explicit Artifact (Late 2000s — Early 2010s)
Opaque tokens were introduced as portable identity references. A token was random, opaque, meaningless string, issued by the auth service, carried explicitly by the client (usually in headers).
Authorization: Bearer a9f3c8e1c2…
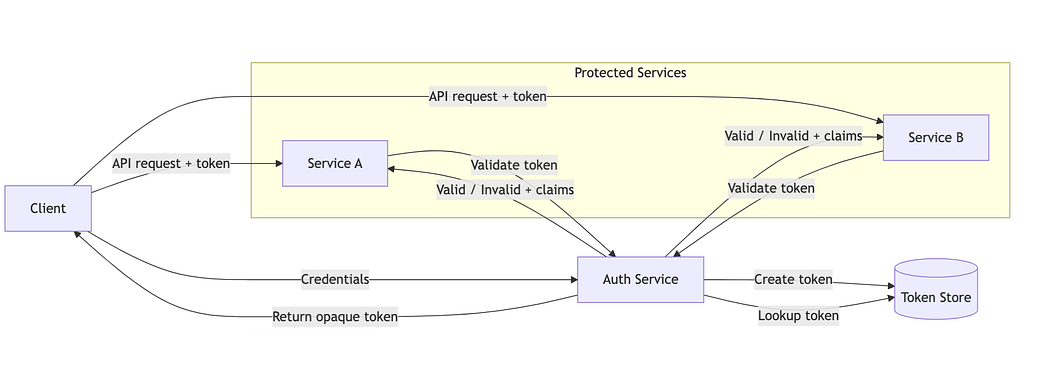
What opaque tokens solved
Identity no longer depended on browsers.
APIs could be called by any client.
Individual services did not store session state.
What opaque tokens broke
Every request still depended on the auth service.
Token validation added network latency.
Auth service remained a shared failure domain.
Internal services could not verify tokens independently.
Opaque tokens removed state sharing, but not verification coupling to auth service.
What changed
As systems continued to scale:
Request rates increased.
Internal service-to-service calls multiplied.
Auth services became hot paths.
Latency budgets tightened.
Identity still required a runtime dependency on auth service.
Systems needed a way to:
validate identity locally.
remove the auth service from the request path.
keep identity portable.
preserve API friendliness.
This led to self-describing tokens.
Tokens (Self-Describing): Identity Carries Its Own Proof (Early–Mid 2010s)
Self-describing tokens were introduced to remove the auth service from the runtime request path.
Instead of being a reference that needed validation elsewhere, the token itself contained enough information for a service to verify identity locally.
A self-describing token was a structured token (commonly Json Web Token, JWT), issued by the auth service, carried explicitly by the client and verifiable without calling the auth service.
The token typically contained identity claims (user, roles, scope), metadata (issuer, expiration, audience) and a signature proving authenticity.
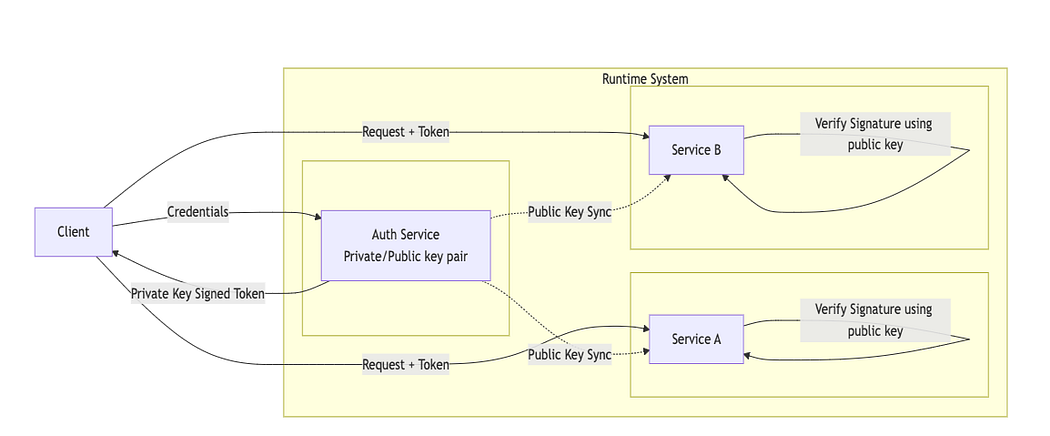
What self-describing tokens solved
Services could verify identity without calling auth service.
Auth service was removed from the hot path.
Latency became predictable.
Horizontal scaling became easier.
Identity worked equally well for browsers and APIs.
This was a major architectural shift.
What self-describing tokens broke
Tokens became visible to clients.
Revocation became non-trivial.
Claims were valid until expiration.
Fine-grained, immediate invalidation was difficult.
Authorization logic risked drifting across services.
Identity became decentralized → but also harder to control centrally.
If you have any feedback on the content, suggestions for improving the organization, or topics you’d like to see covered next, feel free to share → I’d love to hear your thoughts!